1. 모델 경량화와 Quantization: 심층 신경망 최적화를 위한 전략
최근 인공지능(AI)과 딥러닝 기술이 폭발적으로 발전하면서, 높은 정확도를 자랑하는 대규모 신경망 모델들이(ChatGPT, DeepSeek 등) 각광받고 있습니다. 그러나 이러한 모델들은 높은 메모리 사용량, 전력 소모 그리고 긴 추론 지연(latency) 등의 문제점을 내포하고 있습니다. 이에 대한 해결책으로 모델 경량화 기술이 연구되고 있으며, 그 중 Quantization(양자화)는 대표적인 기법으로 주목받고 있습니다.
2022년 ChatGPT의 등장은 인공지능 기술이 실제로 상용화되어 사람들에게 널리 알려지게 된 전환점 되었으며, 이후 대중의 일상에도 인공지능 기술이 더욱 가까워지고 있습니다. 하지만 인공지능이 우리 생활에 깊숙이 스며들기 위해서는 휴대폰, 모바일 로봇, 드론 등과 같은 엣지 디바이스에서의 원활한 구현이 필수적입니다. 이러한 자원 제한 환경에서는 대규모 신경망을 그대로 구동하기 어려워, 경량화된 모델의 필요성이 대두되고 있습니다.
Quantization은 고정밀의 부동소수점(Floating Point) 연산을 낮은 비트의 고정소수점(Fixed Point) 연산으로 변환함으로써, 모델의 크기와 연산 복잡도를 획기적으로 줄이고 에너지 효율성을 높이는 기술로 주목받고 있습니다. 비록 미래의 컴퓨팅 파워가 현격하게 발전한다 하더라도, 당분간은 인공지능 상용화를 위한 필수 연구 분야로 Quantization이 자리잡을 것입니다.
모델을 경량화하기 위해서 Quantization만이 유일한 대응책은 아닙니다. 하지만 Quantization이 그 중에서도 성능의 전후차이가 크다고합니다.
2. Quantization의 Motivation
딥러닝 모델을 배포할 때, 가장 큰 문제 중 하나는 Computation과 Memory 사용량입니다. 우리는 어떻게하면 높은 Accuracy를 유지하면서도 Computation과 Memory를 줄일지에 대해서 생각합니다. 이를 해결하기 위한 방법 중 하나가 Quantization입니다. Quantization에 앞서 CNN과 MLP를 먼저 생각해보겠습니다. 단순히 CNN이 이미지 처리에서 MLP보다 뛰어나다의 성능의 관점이 아니라 Computation과 Memory 관점에서 보겠습니다.
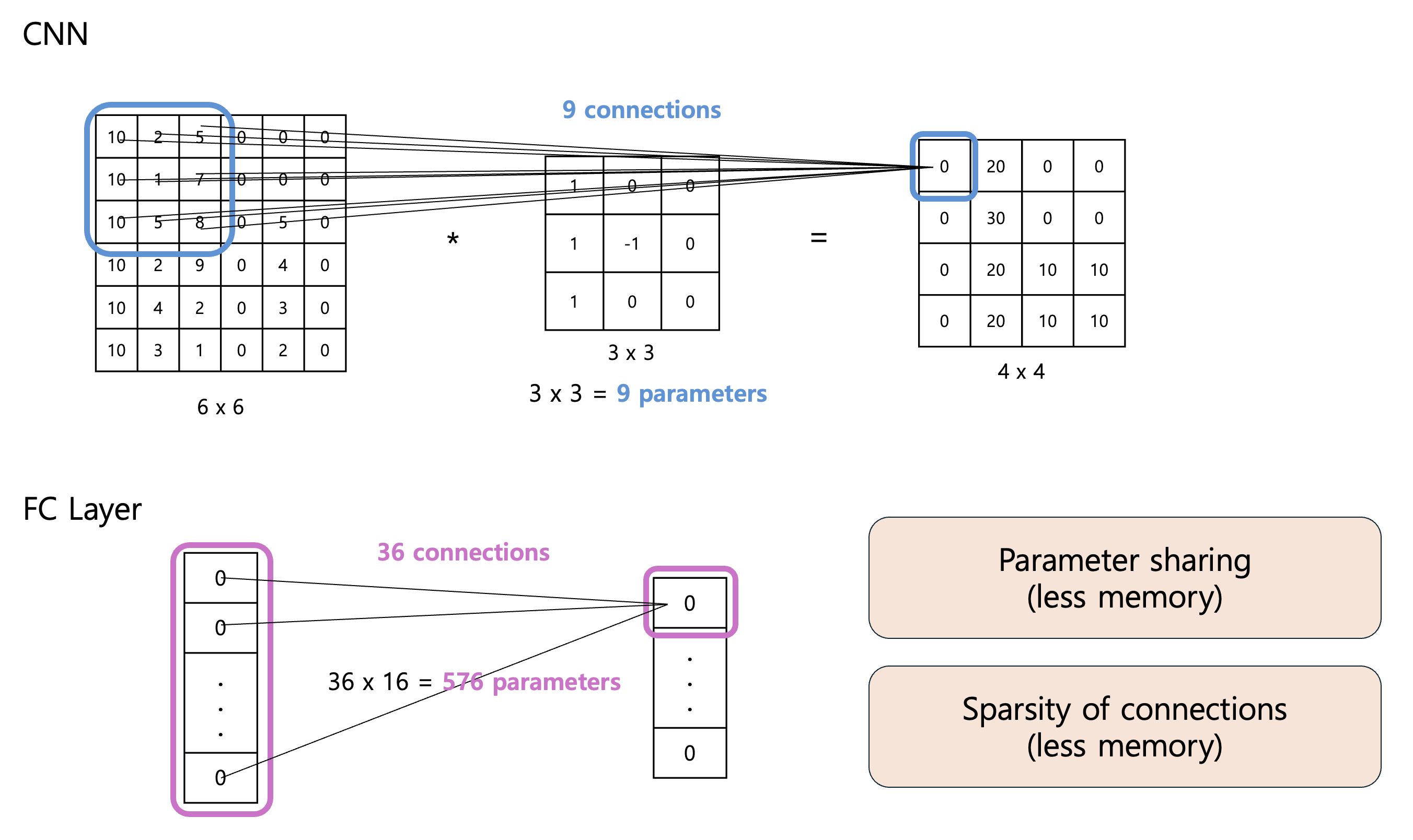
- CNN의 Parameter sharing과 Sparsity of connections라는 두 가지 특징은 MLP에 비해서 Computation과 Memory 관점에서 더 효율적인 아키텍처라고 볼 수 있습니다.
- Parameter sharing : CNN은 필터(Filter)가 여러 위치에서 공유되므로, 같은 크기의 입력과 출력을 가진 MLP보다 적은 수의 가중치(weight)만을 필요로 합니다. 위 그림 상단과 같이 6x6 크기의 입력이 있을 때, 3x3 필터를 사용하면 CNN은 9개의 parameter만 필요합니다. 반면, FC Layer는 36개의 입력 노드를 16개의 출력 노드로 변환하는데 576개의 parameter가 필요합니다.
- Sparsity of connections : 또한, CNN의 경우 1개의 출력을 만들기 위해서 9개의 connection만이 필요합니다. 하지만 FC Layer에서는 1개의 출력을 만들기 위해 36개의 connection이 필요합니다.
- 이러한 2가지 특징으로 인해 CNN이 MLP에 비해서 computation과 memory를 적게 소모하게 됩니다. 그런데도 성능이 좋습니다. Regularization 효과도 있고, 이미지를 처리할 때는 직관적으로 local한 이미지들을 잘 보고 점차 줄여나가면서 전체를 보는 것이 충분히 좋은 approch라는 것이 알려져 있습니다. 항상 전체 이미지를 분석하는 것은 낭비일 수 있습니다.
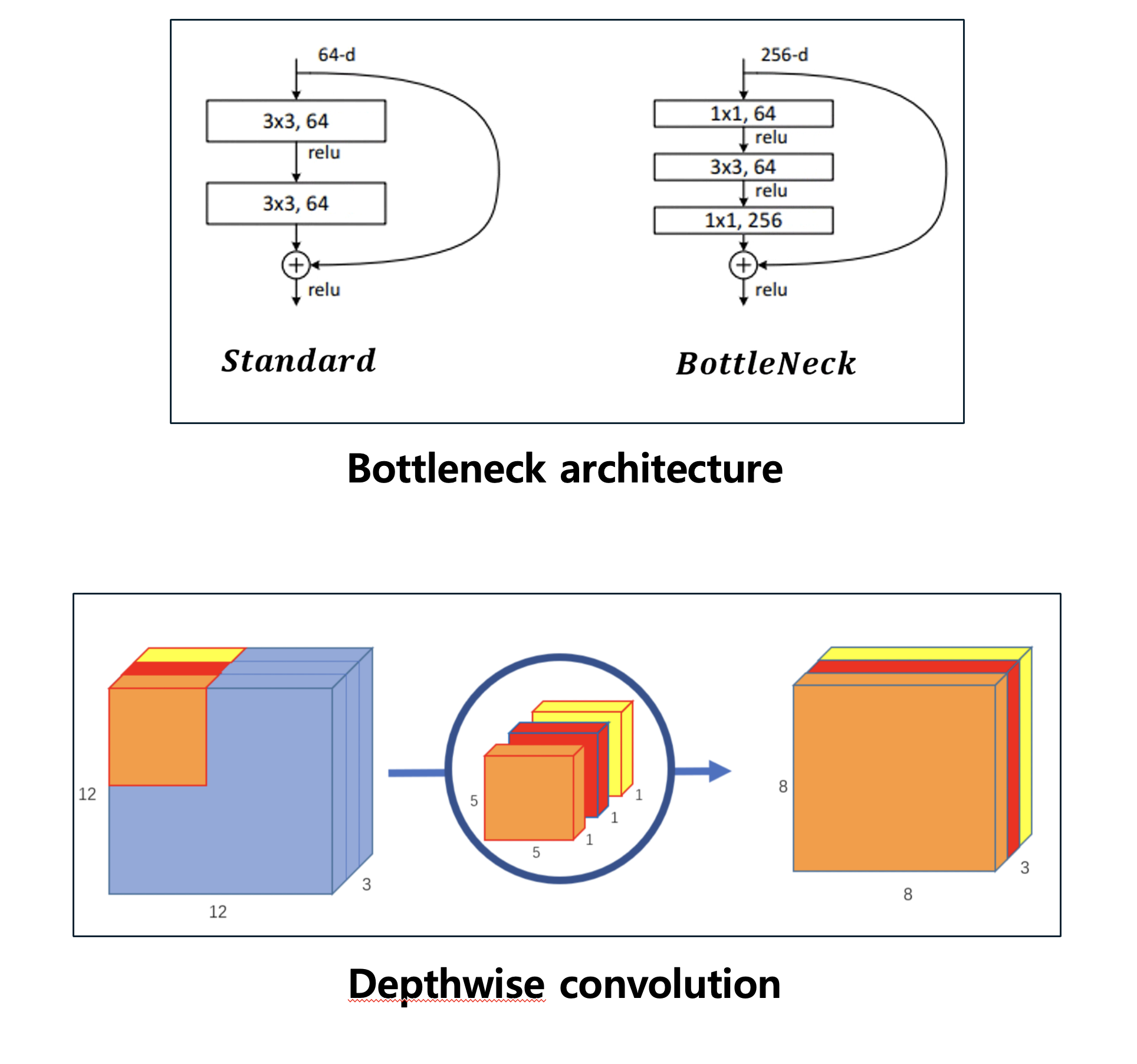
- 또한, CNN도 MLP에 비하면 상당히 가볍습니다. 하지만 이러한 CNN도 여전히 무겁다고 생각하여 여러가지 최적화를 위한 방법들이 나왔습니다. Bottlenect architecture와 Depthwise conv이 그 예시입니다. 이러한 기법들은 아키텍처의 깊이를 더 깊게 만들 때 발생하는 computation 문제를 해결하고자 나왔습니다. 그리고 이것은 사람의 직관에 의해서 만든 것입니다. 절대 수학적인 풀이로 최적화 문제를 풀어서 나온 것이 아닙니다. 그냥 해보니까 되더라 라는.
- 위의 사항들을 고려했을 때, 우선 DNN 자체가 인간의 신경망을 모방해서 연산을 하면 잘 될 것 같다는, 사람의 직관에 의해서 설계된 것입니다. 즉, 우리는 DNN 전체 아키텍처가 전부 필요한지는 전혀 모르는 상태에서 출발했습니다. 단지 성능이 잘 나오기 때문에 출발했던 것이었습니다.
- Lots of computation and memory that a DNN incurs might unnecessary actually : 따라서 CNN이 Bottlenect architecture와 Depthwise conv와 같이 진보했음에도 불구하고, 여전히 연구자들은 질문을 던집니다. 여전히 신경망 아키텍처 어딘가에 우리가 모르는 불필요한 부분이 있을 수 있다라고.
- 또, 이때가지는 connection을 줄이고, Input 사이즈를 줄이는 등의 관점에서 생각을 해봤다면, 다른 관점에서 질문을 던질 수 있습니다. 그것이 Quantization입니다.
- Is it necessary to represent every weight and activation with 32-bit float? : 똑같은 node와 똑같은 input, output 사이즈 일 때, 그것들을 표현하는 단위가 32-bit의 실수로 표현하는 것이 필수적인가? 라는 질문을 던질 수 있습니다.
3. Quantization 이란?
Neural Network Quantization은 딥러닝 모델의 가중치(weights)와 활성화 값(activation)을 높은 정밀도의 Floating Point 표현에서, 상대적으로 낮은 정밀도의 Fixed Point 표현으로 변환하는 기술입니다. 즉, Quantization이란 32bit로 표현되는 Higher precision bits인 Float32 타입(부호 1bit, 지수부 8bit, 가수부 23bit)을 Lower precision bits로 매핑하는 것을 의미한다.
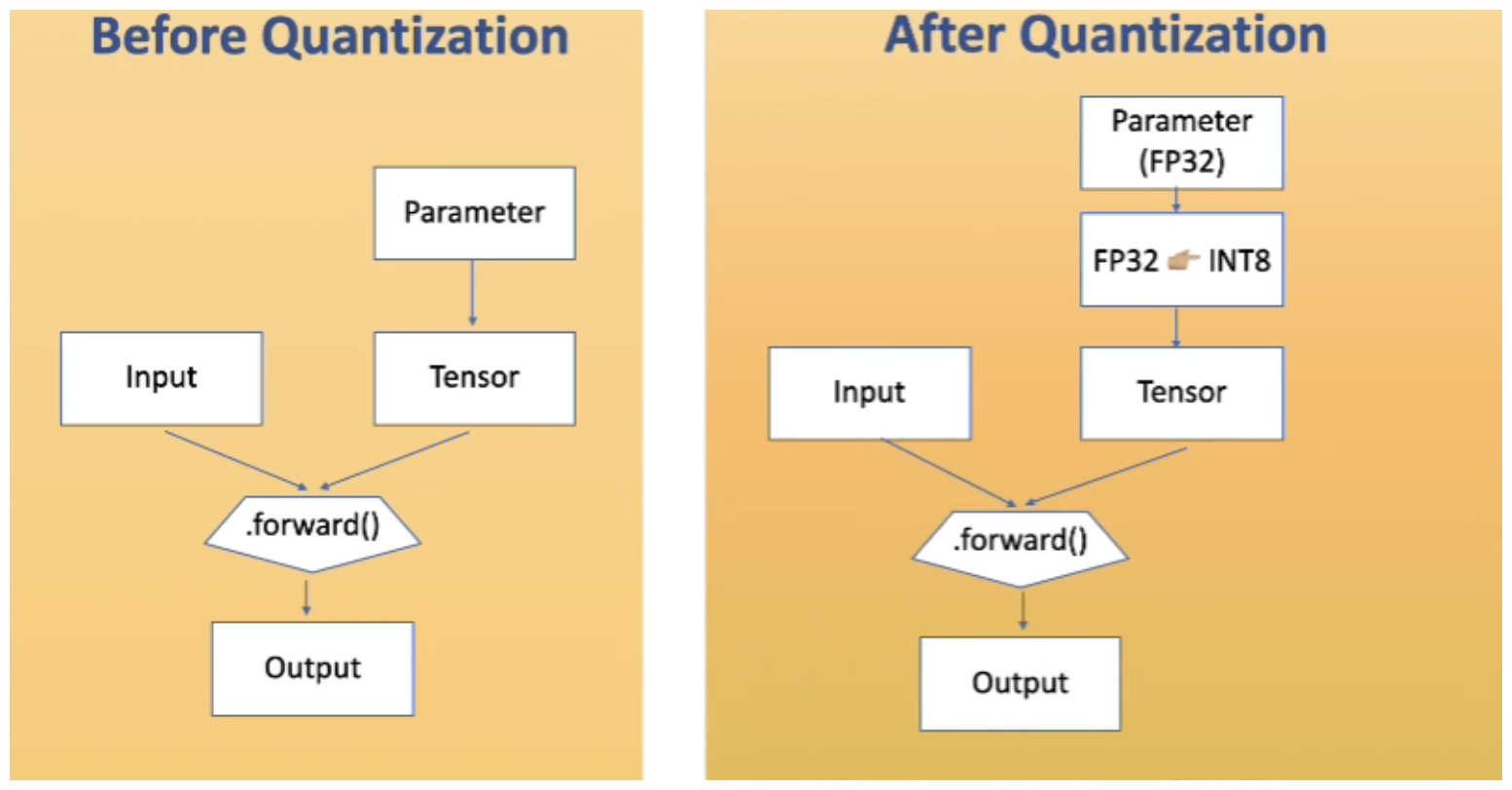
- 위 그림은 모델 파라미터와 텐서를 Quantization하기 전후의 흐름을 보여줍니다. FP32에서 INT8로의 변환 과정이 묘사되어 있습니다. Parameter를 FP32에서 INT8 형태로 변환한 다음에 실제 Inference를 하게 됩니다.
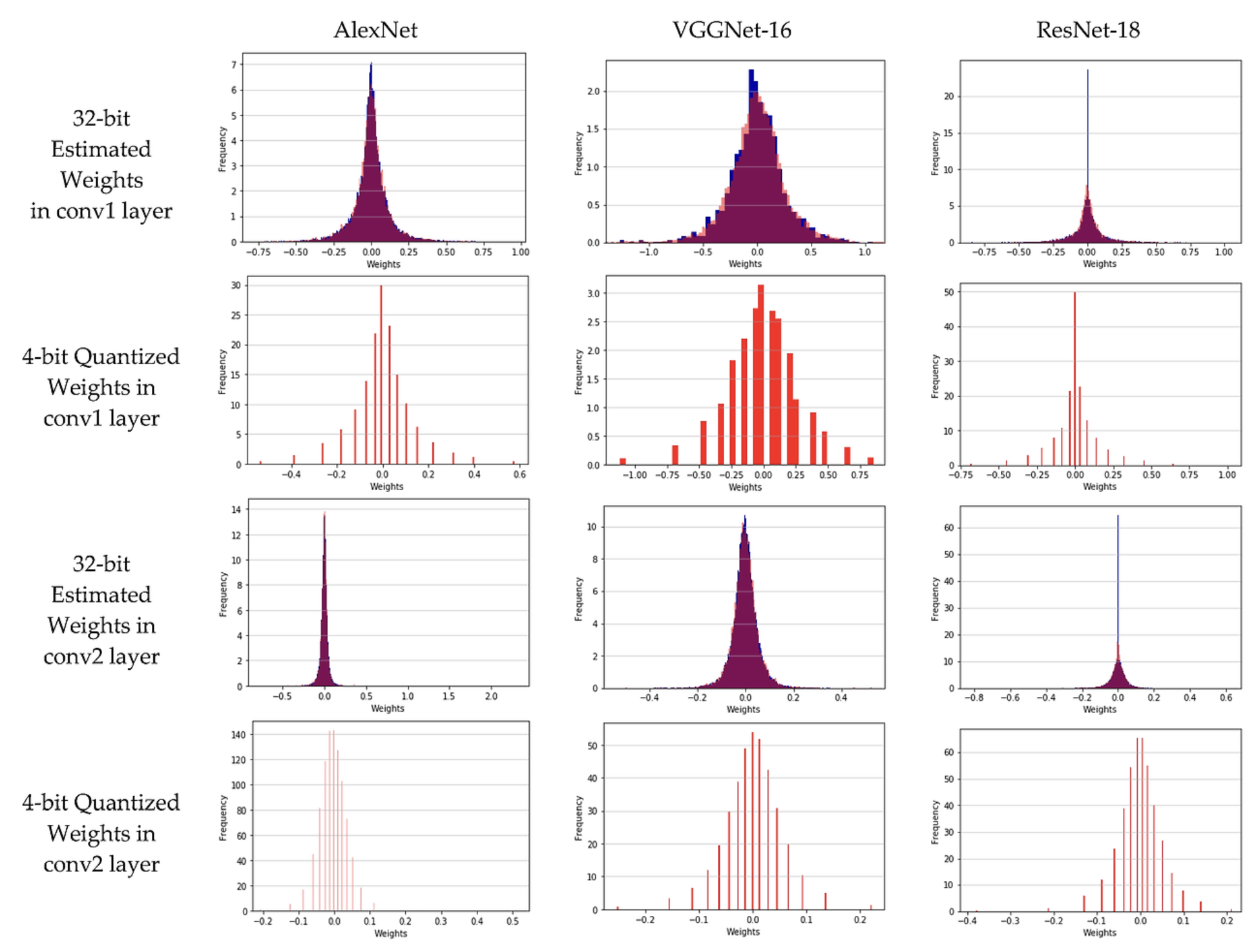
- 위 그림은 세 가지 네트워크 AlexNet, VGGNet-16, ResNet-18의 두 개의 합성곱 레이어에 대해 32-bit 부동소수점(Float Point) 가중치의 분포와 4-bit 양자화된(Quantization) 가중치의 분포를 비교해서 보여줍니다.
- 위 그림에서 1열은 32-bit로 표현된 conv1의 가중치(weight) 분포를 나타낸 것입니다. 2열은 4-bit로 표현된 cov1의 가중치 분포를 나타낸 것입니다.
- 위 그림과 같이 Quantization 과정으로 인해 precision은 낮아지게 되겠지만, weight를 표현하는 데에 사용하는 bit 수가 적어지는만큼 메모리 사용량을 절감시킬 수 있습니다. 이로 모델의 속도를 높일 수 있게 됩니다.
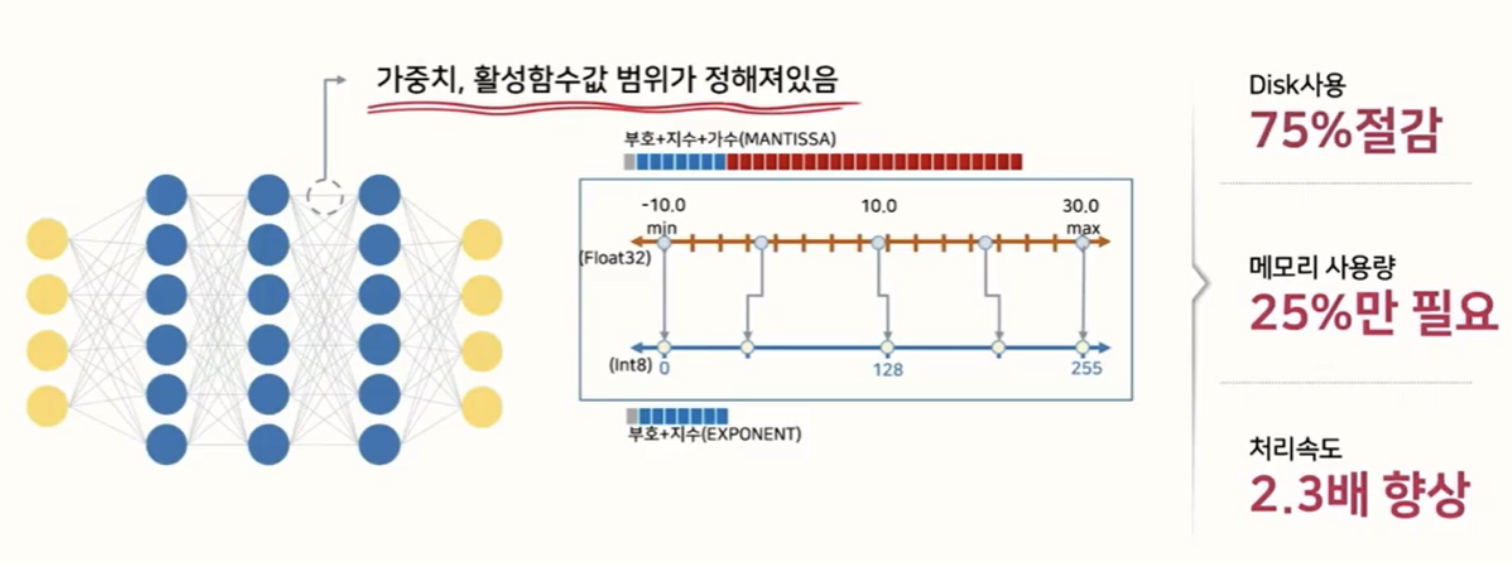
- Int8로 변환하는 Quantization은 8비트 정수(uint8)의 0~255까지만 표현할 수 있습니다. 유한한 비트 수(8비트)로 값을 표현하기 때문에 넓은 범위를 전부 담아낼 수는 없습니다. 따라서 가중치나 활성값이 일정 범위 내에 분포한다고 가정하여, 그 범위만을 정수로 매핑하게 됩니다.
- 가정이라고는 하지만, 실제론 모델의 가중치, 활성값의 통계인 최소값, 최대값을 측정해 '이정도 범위면 대부분의 데이터가 커버된다'는 식으로 범위를 정합니다. 이후에 혹은 양자화 학습(QAT) 과정에서 모델이 스스로 적절한 스케일과 제로포인트를 찾도록 학습할 수도 있습니다.
- 32bit의 정보가 8bit의 정보로 데이터의 크기가 줄어들기 때문에 전체 메모리 사용량 및 처리 속도가 감소하는 효과를 얻을 수 있습니다.
- 이와 같이 Quantization을 통하여 효과적인 모델 최적화를 달성할 수 있습니다.
- Float 타입을 Int 타입으로 변환하면서 bit 수를 줄임으로써 계산 복잡도를 줄일 수 있습니다. 일반적으로 정수형 변수의 비트 수를 N배 줄이면 계산 복잡도가 N * N 배로 줄어든다고 합니다. 디지털 회로에서 정수 곱셈은 비트 단위로 이루어져 있는데, 두 수 (A, B)를 곱할 때, A와 B가 각각 M비트, N비트라고 하면, 단순 논리회로 관점에서 O(M*N) 정도의 복잡도를 가진다고 합니다.
- 즉, 32비트에서 8비트로 줄였을 때 비트 폭이 4배 축소되었으므로, 복잡도는 16배 줄어든다고 볼 수 있습니다. (실제 상용 하드웨어에서는 파이프라인, 캐시, 병렬화 등 다양한 최적화로 인해 정확하 N*N배라고 하긴 어렵지만, 그만큼 회로가 간단해지고, 빨라지고, 전력 소모가 감소한다는 점은 일반적으로 참임.)
- 또한, 정수형 타입은 하드웨어에 더욱 친화적입니다.
- 정수 연산은 하드웨어 구조가 단순하고, 부동소수점 연산은 부호, 지수, 가수를 처리하는 별도의 복잡한 연산 파이프라인이 필요합니다. 일반적으로 CPU 명령어 집합에서도 정수 연산은 아주 기본적이고 필수적인 반면, 부동소수점 연산은 추가 회로나 마이크로코드가 필요해 연산 레이턴시와 소비 전력이 더 커집니다.
- "뉴럴넷 가중치를 처음부터 정수로 계산하면 되는거 아님?"이라는 질문이 들수도 있습니다. 하지만 신경망은 학습 시에 오차역전파(Backpropagation)을 통해 실수 기반 미분 연산이 필수적입니다. 가중치를 갱신할 때 작은 값의 변화(Gradient)도 포착해야 하고, 이는 연속적인 실수 범위를 전제로 합니다. 만약 처음부터 정수만으로 학습하면, 정밀도가 급격히 낮아지거나, 학습 시 제대로 수렴하지 않을 위험이 큽니다.
- 학습이 끝난 후, 추론에서는 미분이 필요 없고, 가중치가 고정된 상태이므로 정수로 변환해도 큰 문제가 없습니다. 따라서 학습(Training)은 실수 기반으로 해 정확도를 확보하고, 추론(Inference)에만 정수(Quantized) 모델을 쓰는 것이 일반적인 접근입니다.
import time
t1 = time.time()
print(5.142839587 * 4.128394058)
t2 = time.time()
print(5 * 4)
t3 = time.time()
print(format(t2 - t1, '.9f'))
# 0.000023842
print(format(t3 - t2, '.9f'))
# 0.000001907
print(format((t2 - t1) / (t3 - t2), '.9f'))
# 12.500000000
- 실제로 Neural Network의 경우 Matrix multiplication 연산을 매우 많이 하게 됩니다. 위 코드를 통해 왜 Neural Network의 Inference 시 Quantization이 필요한지 볼 수 있습니다.
- 위 코드와 같이 실수 연산과 정수 연산을 단 1개만 비교하는 경우에도 정수 연산은 소수 연산에 비해 12.5배 빠르게 연산이 되는 것을 확인할 수 있습니다.

- Quantization에서 Accuracy와 Model size에 대한 메트릭을 보도록 하겠습니다. 위 그림은 여러 신경망 아키텍처(ResNet 시리즈, VGG-16bn, SqueezeNext 등)를 다양한 비트 정밀도(2, 3, 4, 8비트)로 양자화했을 때 모델 크기와 Top-1 Accuracy 사이의 관계를 나타낸 것입니다. 그림 오른쪽 아래에 있는 'Full Precision Model Size(MB)'는 각 네트워크의 FP32(Full precision) 기준 모델 크기(MB)가 참고용으로 제시되어 있습니다.
- 위 그림이 제시된 논문에서 제시한 인사이트는 2bit로 Quantization 된 ResNet-34와 ResNet-50은 "더 작은 네트워크를 더 높은 정밀도(bit)로 쓰는 경우보다도 정확도가 높아 절대적인 장점을 보이는 것으로 나타난다는 것입니다.
- 즉, ResNet-34와 ResNet-50에서는 낮은 크기의 모델을(예: ResNet-18) 양자화 하는 것보다 사이즈가 큰 모델을 2비트와 같이 양자화를 깊게 하는 것이 이득일 수 있다는 것입니다.
- 또한, Full precision인 FP32에서 Int8로 Quantization을 한다면 모델 사이즈는 1/4이 됩니다.
3. Quantization 세부 사항
1. Inference only : Quantization은 Inference에서만 사용합니다. 즉, 학습(Training) 시간을 줄이기 위한 것과는 관련이 없습니다.
2. Not every layer can be quantized : 구현한 딥러닝 모델의 모든 layer가 quantization이 될 수 없는 경우가 있습니다. 이것은 각 layer 자체의 특수성으로 어려운 부분도 있지만 PyTorch와 같은 Framework가 지원하지 않는 경우도 있습니다.
3. Not every layer should be quantized : 비록 quantization이 가능한 layer라도, 모든 layer에 무조건 quantization 하는 것이 최적의 결과를 가져다 주는 것은 아닙니다. 예를 들어, 입력층이나 출력층, 또는 특정 민감한 layer는 full precision을 유지하는 것이 전체 모델 성능(정확도)을 보존하는 데 도움이 될 수 있습니다. 경우에 따라서는 여러 layer를 하나로 결합(fusion)한 후에 quantization을 적용하면, 중간에 발생할 수 있는 quantization error를 줄여 더 효율적인 최적화를 달성할 수 있습니다.
4. Not every model reacts the same way to quantization : 동일한 quantization 기법을 적용하더라도, 모델의 구조나 layer 구성에 따라 quantization의 영향은 다르게 나타납니다. 일부 모델은 quantization에 상대적으로 강인하여 큰 정확도 손실 없이 최적화할 수 있지만, 다른 모델은 미세한 정밀도 손실에도 성능이 크게 저하될 수 있습니다. 각 layer의 특성이 있기 때문에 layer의 집합인 model에서는 그 현상이 더 크게 나타납니다. 따라서 각 모델에 대해 quantization을 적용하기 전에 충분한 실험과 튜닝이 필요합니다.
5. Most available implementations are CPU only : 많은 quantization 라이브러리나 구현체는 아직 CPU에서 최적화되어 있습니다. 이는 정수 연산이 CPU의 ALU에서 효율적으로 동작하기 때문이며, 초기에는 GPU나 다른 가속기에서의 지원이 제한적이었습니다. 최근에는 GPU, TPU, 전용 AI 가속기 등에서도 저정밀도 연산(INT8, INT4 등)을 위한 하드웨어 최적화가 진행되고 있지만, 여전히 많은 경우에 CPU 기반 quantization이 보편적으로 사용되고 있습니다.
참조
https://gaussian37.github.io/dl-concept-quantization/
https://www.youtube.com/watch?v=91_hhex0CmU&t=1s
https://www.youtube.com/watch?v=Xy6ReeKo6xk
https://arxiv.org/pdf/2103.13630
https://arxiv.org/pdf/1902.08153
https://www.mdpi.com/2076-3417/9/12/2559