한 번 할 때 제대로 이해해놓기 위한 정리. 다음에 가물가물할 때 다시 볼 수 있도록.
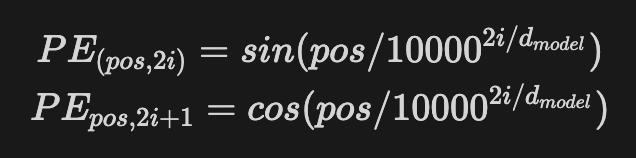
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp( torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model) )
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
seq_len = x.size(1)
x = x + self.pe[:, :seq_len]
return x
1. Transformer 모델은 왜 위치 정보가 따로 필요한가?
- Transformer의 핵심은 Self-Attention 메커니즘이다. 이 Self-Attention 메커니즘은 입력 시퀀스의 각 토큰을 서로 비교(유사도 계산)하여 관계를 학습함. 그런데 이 Self-Attention 자체는 순서를 인식하는 구조가 없음.
- 집합(set) 연산처럼 동작하기 때문임. 즉, 입력 토큰 순서를 바꾸더라도, 토큰 간의 상호 작용(Attention 계산) 자체는 토큰들 간의 관계만 보고 이루어짐. (순서는 무시한 채). I Love You 나 You I Love나 그냥 토근들 간의 관계만 학습하게 된는거임.
- 모델 입장에서는 1번째, 2번째와 같은 순서를 알 수 있는 장치가 내부가 존재하지 않는 것임. (이를 순열 등변성이라고 부름, permutation equivariant)
- 크게 보자면, 병렬 처리를 하기 때문에 순서를 인식하는 구조를 가질 수 없는 것임. 작은 것을 버리고 큰 것을 취한 것임.
- Transformer가 기존 RNN(Recurrent Neural Network, 순환신경망)과 달리 병렬 처리가 가능한 이유가, 토큰 간 순서 의존을 제거하여 한꺼번에 토큰 간의 상호작용을 계산하기 때문임.
- 병렬 처리라는 장점이 있지만, 반대로 순서 정보가 내장되어 있지 않으므로, 이를 Positional Encoding을 통해 위치 정보를 명시해 줘야함.
2. 순서가 필요하다.
- 자연어에서는 '이 문장에서 어떤 단어가 어디에 위치하는가'는 의미를 해석할 때 매우 중요한 정보임.
- Self-Attention 메커니즘으로는 '이 단어가 몇 번째 토큰인가' 같은 절대 위치, 상대 위치를 알 수 없음.
- 절대 위치는 위치 1, 위치 2, 위치 3과 같은 정보이고, 상대 위치는 위치 1의 단어와 위치 3의 단어와의 상관관계임.
- 또한, 2번 토큰이 3번 토큰보다 앞에 온다는 사실을 인식해야 하는데, 순서 정보를 주지 않으면 단순히 두 토큰 간의 유사도만 계산할 뿐, 누가 먼저이고 누가 나중인지를 구분하지 못함.
- "The cat sat"과 "Sat cat the"는 동일한 결과를 생성할 수 있음.
- 즉, Transformer 모델에는 순서(위치) 정보가 반드시 필요함. 이 순서 정보를 위해 Positional Encoding이 고안되었음.
3. Positional Encoding의 요구사항
- 어떻게하면 Transformer 모델에게 완벽한 Positional Encoding을 선사할 수 있을까?
- 1. 고유한 Positional Encoding 2. 위치 간의 선형 관계 3. 긴 시퀀스에 대한 일반화 4. 모델이 학습할 수 있는 결정론적( Deterministic) 과정 5. 다차원 데이터로의 확장성
1. 고유한 Positional Encoding
- 시퀀스 길이에 상관없이, 각 위치는 고유한 인코딩 값을 가져야 함.
- 예를 들어, 시퀀스의 길이가 10이든 10000이든, 5번째 위치의 토큰은 동일한 인코딩을 가져야 함.
2. 위치 간의 선형 관계
- 위치 p와 p + k 사이의 관계가 수학적으로 직관적이어야 함.
- 예를 들어, '5가 3에서 2단계만큼 떨어져 있다', '10이 15에서 5단계만큼 떨어져 있다'는 것을 단순 수학 연산으로 표현 가능해야 함.
3. 긴 시퀀스에 대한 일반화
- 모델이 훈련 시 보지 못한 길이의 입력이 들어와도 잘 작동해야 함.
- RNN처럼 입력 길이에 따라 인코딩을 점진적으로 만드는 방식이 아니라 sin, cos 같은 주기 함수를 이용해 무한히 확장할 수 있어야 함.
4. 모델이 학습할 수 있는 Deterministic 과정
- 위치 인코딩은 매우 복잡하거나 랜덤적이지(stochastic) 않고, 결정론적(Deterministic) 형태여야 모델이 편리하게 학습할 수 있음.
- sin, cos 함수는 위치가 달라짐에 따라 값이 예측 가능하게 변함.
5. 다차원 데이터로의 확장성
- 자연어뿐만 아니라 이미지, 영상 등에서도 인코딩을 할 때 쉽게 확장되야 함.
4. 오리지널 논문의 Positional Encoding

1. 왜 sin, cos 함수를 사용하는가?
- 주파수 형태로 순서를 주입하면, 다양한 간격에 대해 토큰 간의 위치 관계를 자연스럽게 반영할 수 있음.
- sin과 cos은 서로 위상이 직교이기에, 즉, 90도( π/2 )만큼 차이가 있어서, 한 축이 0일 때 다른 축은 최대값이 되는 등 상호 보완적이며, 위치 정보를 다차원적으로 표현할 수 있음.
- sin은 짝수 차원에서 사용하고, cos은 홀수 차원에서 사용함.
- 상호보완적이라는 말은 sin은 특정 값에서 빠르게 변할 때, cos은 안정적인 값을 제공하고, cos이 빠르게 변할 때, sin은 안정적인 패턴을 유지함. 이를 통해 위치를 더 다양하게 구별할 수 있음.
- sin과 cos을 모두 사용하는 이점은, 위치 정보의 표현력이 증가하고 모델이 위치 간의 관계를 더 잘 학습할 수 있게 함.
- sin과 cos이 Transformer 모델에서 처음으로 위치 정보로 사용된 것은 아님.
- 신호 처리(푸리에 변환), 컴퓨터 그래픽스(좌표 변환), 로봇 공학(경로 계획) 등 다양한 문제에 널리 사용되고 있었음.
2. 왜 10000이라는 숫자를 쓰는가?
- 논문에서 제안하는 수식에서 '주파수를 만드는 스케일(스케일링 팩터)'로 10000을 사용함.
- 특정한 과학적 근거가 있어서 사용한 것보다는, 실험을 통해 경험적으로 충분히 적당히 값으로 제안된 것임.
- 예를 들어, 10000이라는 숫자를 20000으로 단순히 늘리면, Positional Encoding의 주기와 관련된 특성이 변하지만, 문제를 해결하지 못할 수도 있음.
- 10000을 20000으로 늘리면, 주파수가 더 낮아지고, 위치 변화에 대한 민감도가 감소함.
- 즉, 위치 값의 변화가 모델에 덜 영향을 미치게 될 수 있다는 의미임. 이는 학습이 제대로 되지 않을 일말의 가능성이 생기는 것일 수도 있음.
3. 10000으로는 몇 개의 토큰 위치까지 표현 가능한가?
- 우선 실무적으로는 문장 최대 길이를 512, 1024, 4096 등으로 제한하는 경우가 많으므로, 10000이라는 스케일은 충분한 편임. 그래도 궁금하니 알아보도록 함.
- 낮은 차원 (i = 0) : 주기 = 2π * 10000^0 = 2π --> 위치 변화에 민감하지 않음.
- 중간 차원 (i = 256) : 주기 = 2π * 10000^1 = 2π * 10000 --> 최대 약 10000개의 위치를 표현 가능
- 낮은 차원에서는 큰 위치 변화에서도 천천히 변화하고, 높은 차원일수록 위치를 더 세밀히 표현할 수 있음.
- 그럼 10000을 20000으로 늘리면 더 많은 토큰에 대한 위치 정보를 제공할 수 있지 않을까?
- 단순히 20000으로 늘리는 것은 일부 효과가 있을 수 있지만, 긴 시퀀스 문제를 근본적으로 해결하진 못함.
- 이에 대한 후속 연구로 RoPE(Rotary Positional Encoding) 등이 있음.
4. "512 차원이라는게 뭐야? 토큰 하나에 위치 정보가 512개?
- 흔히 d_model = 512는 모델 차원이라고 표현함
- 이는 하나의 토큰 벡터가 512차원(512개의 실수)으로 표현된다는 뜻이며, Positional Encoding도 동일한 512차원을 가짐.
- 즉, 토큰 위치를 512차원에 걸쳐서, 각 차원에서 다른 주기를 가지는 sin, cos 파형을 만들어 준다고 보면 됨.
- 이 조합은 각 위치마다 고유한 패턴을 형성하며, Transformer가 위치 정보를 학습할 수 있게 함.
- 낮은 차원은 긴 주기(큰 스케일)로, 높은 차원은 짧은 주기(세밀한 스케일)로 위치를 표현함.
- 이 다층적 표현 덕분에 모델은 상대적 거리 정보와 글로벌 위치 정보를 모두 학습할 수 있음.
5. 단순히 숫자일 뿐인데 컴퓨터가 이게 위치 정보인지 어떻게 아는가?
- 컴퓨터가 단순히 숫자로 이루어진 Positional Encoding을 위치 정보로 이해할 수 있는 이유는 Self-Attention 메커니즘이 입력된 숫자들 간의 관계를 학습할 수 있기 때문임.
- Positional Encoding은 위치 정보를 숫자 벡터로 변환한 것에 불과함. 하지만 이 숫자는 입력 데이터에 규칙적인 패턴을 부여하며, 특정 위치 간의 관계를 드러냄.
- sin, cos 함수의 주기적 패턴 덕분에 위치 간 상대적인 차이를 나타냄.
- Positional Encoding이 입력 토큰에 결합되면, 모델은 위치에 따라 달라지는 패턴을 통해 위치 의존적 관계를 학습함.
5. 다른 방식
- Integer Position Encoding
- Binary Position Encoding
- 절대위치 vs 상대위치 : 최근에는 상대적 위치 인코딩(Relative Positional Encoding) 또는 RoPE(Rotary Positional Encoding) 등이 주목받는 중.
6. "2157번째 단어라는 절대 위치" vs "주변 단어와의 관계"
- “이 문장에서 특정 단어가 몇 번째 위치인지”의 절대적인 위치는 대개 의미적으로 중요한 정보가 아닐 수 있음.
- 실제 언어 해석에서 중요한 것은 “이 단어가 주변 단어와 어떤 관계를 맺느냐”임.
- 그래서 절대 위치보다도 상대적 순서나 인접 토큰 맥락이 언어 이해에 더 핵심적임.
- 다만 “문장의 처음이나 끝에 등장한다” 같은 정보(절대 위치)가 필요한 경우도 있으므로, Transformer는 양쪽을 모두 고려할 수 있도록 설계됨.
7. 결론!
- Self-Attention 메커니즘 자체는 입력 시퀀스의 순서를 전혀 몰라도 병렬적으로 동작할 수 있어, RNN 대비 학습 속도가 빠르고 효율적임.
- 그러나 그 대가로 순서 정보 부족 문제가 생김.
- 이를 해결하기 위해 Positional Encoding(sin, cos)을 활용하여, 모델에 “토큰이 몇 번째 위치인지, 또는 토큰 간 상대 거리가 어느 정도인지”를 알려줌.
- 모델은 학습 과정에서 이 위치 신호를 이용해 시퀀스 내에서 “앞/뒤 토큰 관계”, “토큰 간 거리” 등 여러 정보를 추론할 수 있게 됨.
- 나아가 다양한 변형(Positional Embedding, RoPE, Relative Position Encoding 등)을 통해 확장성과 일반화를 높이는 연구들이 이루어짐.
'Deep Learning > Transformer' 카테고리의 다른 글
| [Transformer] Transformer 코드 리뷰 (1) | 2025.02.14 |
|---|---|
| [Transformer] Transformer의 다양한 Attention (1) | 2025.02.06 |
| [Transformer] Transformer 왜 개발함? (0) | 2025.01.30 |