Transformer는 자연어 처리(NLP)에서 놀라운 성능을 보여주는 대표적인 모델 구조로, 이 안에는 여러 종류의 Attention 메커니즘이 내재되어 있음. 특히 Multi-Head Attention을 중심으로 Encoder와 Decoder 각각의 역할에 맞춰 세분화된 Attention을 사용함. 그렇다면 왜 Transformer에는 이렇게 다양한 Attention이 필요하며, 각각의 Attention은 어떤 방식으로 작동하는 걸까? 그리고 어떤 점에서 미래 단어를 마스킹해야만 할까? 이 글에서는 이러한 질문들에 대해 깊이 있는 설명을 해보도록 하겠음.
왜 Transformer에는 다양한 Attention이 쓰여야만 했을까?
Transformer 이전의 전통적인 RNN(Recurrent Neural Network) 계열 모델들은 긴 문장이나 복잡한 문맥을 처리하기 어려웠음. LSTM이나 GRU와 같이 개선된 RNN 구조도 여전히 ‘정보의 흐름을 순차적으로 처리’한다는 제약이 존재함. 이 때문에 문장이 길어지면 처음 부분의 정보가 후반부로 전달되는 과정에서 소실되거나 왜곡될 수 있었음.
Self-Attention을 기반으로 한 Transformer는 병렬 연산이 가능하도록 만들어, 긴 문장도 한 번에 처리할 수 있는 장점을 얻었음. 그러나 문장을 처리하고 이해하는 과정은 단순하지 않음. 어떤 토큰(단어)은 시제나 형태에 집중해야 하고, 어떤 토큰은 문장의 구조나 관계에 집중해야 하는 등 다양한 관점이 동시에 필요함. 그렇기 때문에 Transformer 구조 내에서 서로 다른 ‘관점(Attention Head)’들을 활용할 수 있도록 다중화(Multi-Head)된 Attention을 사용함.
이 뿐만 아니라 Encoder와 Decoder는 각각 다른 역할을 하므로, Encoder에는 Encoder용 Self-Attention(이 글에서는 ‘Encoder Multi-Head Attention’이라 표현)과 Feed-Forward Network가, Decoder에는 문장 생성을 위한 Masked Multi-Head Attention(Decoder용 Self-Attention)과 Encoder로부터 정보를 받아오는 Encoder-Decoder Multi-Head Attention 그리고 Feed-Forward Network가 함께 구성되어 있음. 문맥을 풍부히 이해하고 적절히 단어를 생성하기 위해서는 이런 다양한 Attention 메커니즘이 유기적으로 함께 작동해야 함.
그럼 순서대로 자세히 알아보도록 하자.
Multi-Head Attention이란 무엇인가?
우선 Transformer의 핵심 아이디어 중 하나인 Multi-Head Attention은 말 그대로 “하나의 Attention을 여러 개의 Head(독자)로 병렬적으로 수행하는 것”을 뜻함. 단일 Attention만으로는 포착하기 힘든 다양한 문맥적 관계를 여러 Head들이 각각 독립적으로 파악할 수 있게 됨.
하나의 Head가 문장 구조에 집중한다면, 다른 Head는 명사에 집중하고, 또 다른 Head는 문장 내 관계성을 집중적으로 살피는 식임. 이렇게 여러 Head가 동시에 서로 다른 정보를 추출해내면, 최종적으로 결합(Concatenate)했을 때 더 풍부하고 다양한 표현력(Representation)을 얻을 수 있음.
예시: 하나의 문장에 여러 Head가 주목하는 방식
“Which do you like the better, coffee or tea?”
- 문장 형태(Type)에 집중하는 Head
- 이 Head는 문장의 의도(질문문), 구조(의문사) 등을 강조하여 문맥을 이해하는 데 도움을 줌.
- “Which do you like the better, coffee or tea?”
- 명사(Noun)에 집중하는 Head
- “coffee”, “tea” 등의 명사나 대상에 주목하여 무엇을 좋아하는지에 대한 정보에 집중함.
- “Which do you like the better, coffee or tea?”
- 관계(Relation)에 집중하는 Head
- “which”와 “coffee/tea” 등의 토큰 간 관계에 더욱 관심을 두어, 어떤 대상을 비교하는 질문인지를 인식함.
- “Which do you like the better, coffee or tea?”
- 강조(Emphasis)에 집중하는 Head
- “like the better” 부분을 강조하거나, 문맥상 중요하게 다뤄야 할 단어에 집중해 정보를 더 정확히 추출함.
- “Which do you like the better, coffee or tea?”
이처럼 한 문장에서 다양한 측면을 동시에 파악할 수 있는 것이 Multi-Head Attention의 가장 큰 강점임. 여러 Head가 각각 다른 종류의 정보를 취합해주기 때문에, 모델의 학습 효과와 표현력 모두 크게 향상됨.
Multi-Head Attention이 왜 필요할까?
- 복잡한 관계(Dependency) 학습: 문장 내에서 단어 간 관계가 복잡하게 얽혀 있는 경우가 많음. Multi-Head를 통해 Head마다 서로 다른 패턴이나 의존 관계를 학습할 수 있음.
- 다양한 특징(Feature) 추출: 어떤 Head는 단어 형태, 어떤 Head는 문맥의 흐름, 또 다른 Head는 화자의 의도 등 다양한 특징에 집중하여 더 풍부한 정보 집합을 얻음.
- 병렬 처리 강화: 여러 개의 Attention Head가 독립적으로 계산되므로, 병렬 처리 관점에서도 효율적임.
Encoder Multi-Head Attention
Encoder는 입력 문장(토큰 시퀀스)의 전체적인 문맥 정보를 정리하는 역할을 담당함. Encoder의 각 레이어는 크게 두 가지 하위 서브 레이어(sub-layer)로 구성됨.
- Multi-Head Attention (Self-Attention)
- Feed-Forward Network
Encoder에서 사용되는 Multi-Head Attention은 흔히 Self-Attention이라고도 부르는데,
- Query(Q), Key(K), Value(V)가 모두 Encoder의 출력(혹은 입력) 토큰에서 만들어짐.
- 학습 시에 WQ,WK,WVW^Q, W^K, W^V라는 세 개의 학습 파라미터 행렬을 통해 각각 Q, K, V로 변환함.
- 이 과정을 Multi-Head로 병렬 수행한 뒤 최종적으로 Concatenate하여 출력함.
Encoder-Decoder Multi-Head Attention
Decoder는 문장을 생성(출력)해야 하는 역할을 맡고 있음. 따라서 Encoder에서 이미 뽑아낸 문맥 정보를 활용해야 하고, 동시에 이전에 생성된 단어들을 이용해 다음 단어를 예측해야 함.
Decoder는 다음 세 가지 하위 서브 레이어(sub-layer)로 구성됨.
- Encoder-Decoder Multi-Head Attention
- Masked Multi-Head Attention
- Feed-Forward Network
이 중에서 Encoder-Decoder Multi-Head Attention은, Query는 Decoder에서, Key와 Value는 Encoder에서 가져오는 독특한 구조임. 이는 다음처럼 표현할 수 있음.
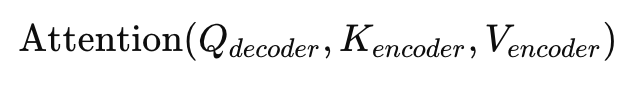
즉, Decoder가 현재까지 만들어낸 문맥(Decoder 출력의 일부)을 Query로 사용하고, Encoder가 만들어 낸 풍부한 문맥 정보를 Key와 Value로 사용함.
- Decoder는 문장을 생성할 때, “어떤 단어를 다음에 생성해야 하지?”라는 질문을 함.
- 이때, Encoder가 미리 정리해 둔 입력 문장의 전체 문맥 정보를 참고해 가장 알맞은 단어를 선택할 수 있게 됨.
예시
예를 들어 “커피를 더 좋아하니, 차를 더 좋아하니?”라는 한글 문장(입력)을 Encoder가 처리했다고 가정해 보자. Encoder는 이 문장으로부터 “질문 구조”, “비교 대상(커피와 차)”, “좋아하는 대상” 등 풍부한 정보를 뽑아 놓았음.
Decoder가 단어를 하나씩 생성하면서 최종 목표(예: “나는 커피를 좋아해.”)를 만들어나갈 때,
- “나는”을 생성하고,
- 다음 단어로 “커피”를 생성할지 “차”를 생성할지 고를 때,
- Query는 현재까지의 Decoder 상태(“나는”)가 되고,
- Key, Value는 “질문 구조와 비교 대상 정보”를 담고 있는 Encoder의 출력이 됨.
Decoder는 “커피”와 “차” 중 어떤 단어가 더 적절한지 Encoder의 Key, Value를 통해 점수를 산정하고, “커피”가 더 맞다는 결론을 내릴 수 있음. 이렇게 Decoder는 계속해서 입력 문장의 정보를 보며 더 정확한 출력을 하게 됨.
Masked Multi-Head Attention
이제 Decoder에만 특별히 존재하는 Masked Multi-Head Attention에 대해 알아보겠음. Decoder는 문장을 왼쪽에서 오른쪽으로 순차적으로 생성(토큰 단위)함. 그런데 Self-Attention 구조 특성상, 모든 토큰끼리 서로 Attention을 주고받을 수 있음. 만약 그대로 두면 아직 생성되지 않은 ‘미래 단어’까지 참고하는 문제가 생기게 됨.
즉, 기존의 Encoder-Decoder 구조의 모델들은(Seq2seq) 순차적으로 입력 값을 전달받기 때문에 t+1 시점(미래)의 예측을 위해 사용할 수 있는 데이터가 t 시점까지로 한정됨. 하지만 Transformer의 경우 전체 입력값을 전달받기 때문에 과거 시점의 입력값으로 예측할 때 미래 시점의 입력값을 참고할 수 있다는 문제가 발생(학습 능력 저하).
그러니까 내가 t + 1 의 단어를 예측하려면 t 시점까지의 과거의 모든 데이터가 하나의 벡터로 뭉쳐서 사용함. 하지만 Transformer는 전체 입력값을 전달받고(인코더에 있는 모든 인풋값 및 예측해야하는 타켓값), t + 1 을 예측하려고 하면, t + 1 이라는 미래의 값까지 미리 알아버림. 이를 해결하기 위해 Masking을 사용함. 미래에 내가 예측할 토큰들을 숨겨버림으로써 해결함(Maksing).
Masking이 필요한 이유
- 자동 완성(Auto-Regressive) 구조 유지: Decoder가 한 번에 문장을 전부 볼 수 있다면, 그 자체가 답안(미래 단어)이 되므로 학습이 무의미해짐.
- 학습 과정에서의 ‘치팅(Cheating)’ 방지: 미래 단어를 알고 있다면, 예측 문제가 아니라 답안 맞추기가 되어버림. 이는 모델이 실제 상황(왼쪽→오른쪽 생성)과 전혀 다른 학습 경로를 택하게 하므로, 제대로 된 언어 생성 능력을 학습하기 어려움. 치팅을 막음으로써 학습 능력을 높여줌.
Upper Triangular Mask(상삼각 마스크)
Softmax를 적용하기 전 단계에서, 현재 토큰보다 오른쪽에 있는(미래의) 토큰들에 대한 Attention 스코어를 -∞(음의 무한대)에 가깝게 설정함.
- 소프트맥스 함수 softmax(x)에서 가 극단적으로 작으면(음의 무한대에 가까우면) 그 값은 0에 수렴함.
- 따라서 미래 토큰들로부터는 어떠한 정보도 가져오지 못하도록 만들 수 있음.

미래 단어를 참고하면 정확히 어떤 문제가 발생하는 걸까?
언어 모델은 원래 ‘다음 단어를 예측’해야 함. 즉, “나는 커피를…”까지 만든 시점에서 다음 단어를 뭘로 해야 할지 고민해야 하는데, 만약 이미 뒤에 있는 단어들(미래)을 볼 수 있다면 ‘미래 단어가 무엇인지 미리 알아버리는’ 일이 벌어짐. 그 결과 모델은 다음 단어를 추론하는 과정을 학습하지 않고, 이미 정답을 훔쳐보게 됨. 이는 실제 테스트 시(미래 단어를 알 수 없는 상황)와 완전히 다른 학습 환경이 되어버려, 모델이 정상적으로 언어 생성 능력을 익히지 못하게 됨.
왜 - ∞로 설정하는 걸까?
마스킹은 어텐션 스코어를 계산할 때, ‘보면 안 되는 토큰’에 대한 가중치를 0으로 만들어 버리기 위함임.
- 소프트맥스의 입력 단계에서 어떤 값이 - ∞ 이면, 소프트맥스 결과가 0이 됨.
- 이렇게 스코어가 0이 되면 해당 토큰은 Attention에서 무시되고, 결과적으로 미래 정보가 전혀 유입되지 않도록 차단할 수 있음.
결론 및 요약
- Transformer에는 다양한 Attention이 존재한다.
- Encoder Multi-Head Attention: 입력 문장(토큰 간의 관계)을 Self-Attention으로 분석.
- Encoder-Decoder Multi-Head Attention: Decoder가 문장을 생성할 때 Encoder의 정보를 참고.
- Masked Multi-Head Attention: Decoder에서 미래 단어를 보지 않도록 마스킹 처리해, 올바른 언어 생성 과정을 학습.
- 왜 이렇게 복잡한 구조를 사용하는가?
- 하나의 Attention으로는 다양한 언어적 특징을 효율적으로 포착하기 어려움.
- 여러 Head가 독립적으로 학습해 다양한 문맥적 관계를 동시에 파악할 수 있음(Multi-Head Attention).
- Encoder와 Decoder는 서로 다른 역할을 하므로, 필요에 따라 Self-Attention, Encoder-Decoder Attention, Masked Attention 등 세부 구조를 달리 적용.
- 마스킹은 왜 필요한가?
- Decoder가 “앞에서 뒤로” 단어를 만들어가는 과정을 지키기 위해서 미래 단어를 가려야 함.
- 미래 단어를 미리 알게 되면 언어 모델로서의 추론 과정을 학습하지 못하고, “치팅” 상태가 되어버려 제대로 된 생성 능력을 배양할 수 없음.
이처럼 Transformer 내부에서의 Attention 메커니즘은 서로 다른 관점을 통해 더 풍부한 정보를 얻고, Encoder-Decoder 간의 정보 흐름을 최적화하며, 미래 단어 참조를 방지하는 등 효율적인 언어 모델링을 위한 핵심 수단임. 앞으로 Transformer 구조를 자세히 살펴볼 때, 어떤 Attention이 어떤 목적으로 쓰이는지 이해하면, 모델이 왜 뛰어난 성능을 내는지 한층 더 명확해질 것임.
'Deep Learning > Transformer' 카테고리의 다른 글
| [Transformer] Transformer 코드 리뷰 (1) | 2025.02.14 |
|---|---|
| [Transformer] Transformer 왜 개발함? (0) | 2025.01.30 |
| [Transformer] Sinusoidal Positional Encoding (0) | 2025.01.14 |