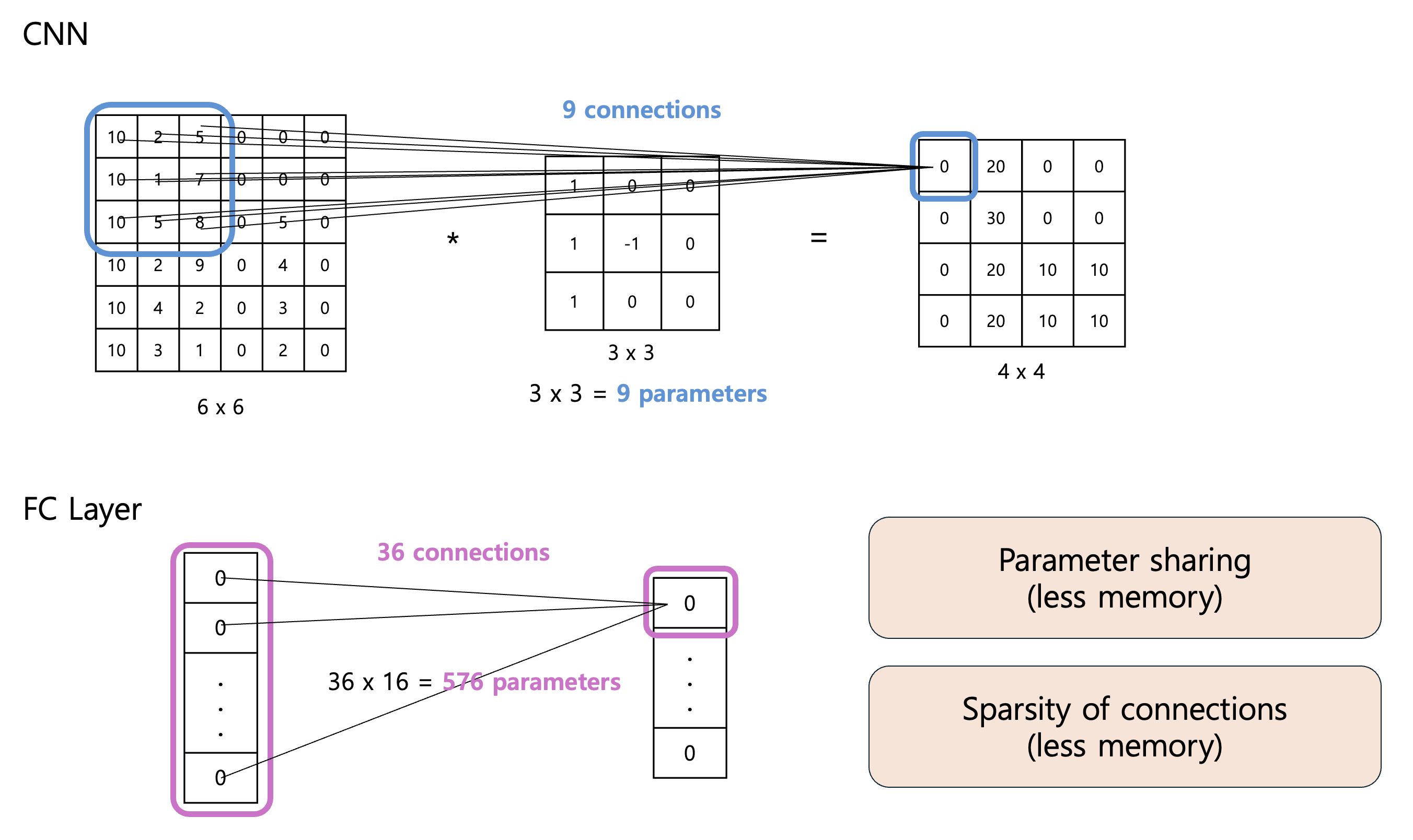
1. 모델 경량화와 Quantization: 심층 신경망 최적화를 위한 전략 최근 인공지능(AI)과 딥러닝 기술이 폭발적으로 발전하면서, 높은 정확도를 자랑하는 대규모 신경망 모델들이(ChatGPT, DeepSeek 등) 각광받고 있습니다. 그러나 이러한 모델들은 높은 메모리 사용량, 전력 소모 그리고 긴 추론 지연(latency) 등의 문제점을 내포하고 있습니다. 이에 대한 해결책으로 모델 경량화 기술이 연구되고 있으며, 그 중 Quantization(양자화)는 대표적인 기법으로 주목받고 있습니다. 2022년 ChatGPT의 등장은 인공지능 기술이 실제로 상용화되어 사람들에게 널리 알려지게 된 전환점 되었으며, 이후 대중의 일상에도 인공지능 기술이 더욱 가까워지고 있습니다. 하지만 인공지능이 우리 ..